随着人工智能(AI)技术在各行各业的深度融合与爆发式增长,数据作为其核心燃料的地位日益凸显。传统计算架构中数据在处理器与内存之间的频繁搬运已成为制约AI性能提升的“内存墙”瓶颈。在这一背景下,存内计算(Processing-In-Memory, PIM)技术正以其颠覆性的架构理念,为人工智能应用,特别是大规模人工智能公共数据平台的构建,开辟了令人瞩目的前景。
一、PIM技术:破解AI计算瓶颈的关键钥匙
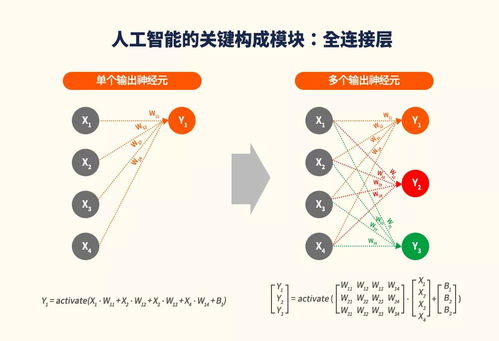
PIM技术的核心思想是将部分计算功能直接嵌入到存储单元或邻近位置,从而极大地减少数据在处理器和内存之间的移动。这种“存算一体”的范式,直接针对了当前AI模型(尤其是深度神经网络)在训练和推理过程中海量权重参数与激活数据频繁访问所带来的巨大能耗与延迟问题。
对于人工智能应用而言,PIM的优势显而易见:
- 极致能效:大幅降低数据搬运能耗,这对于能耗敏感的边缘AI设备和数据中心规模部署至关重要。
- 超低延迟:就地处理数据,显著减少访问延迟,加速模型推理与训练周期。
- 高吞吐量:内存带宽得以充分利用,支持大规模并行计算,满足AI对算力的贪婪需求。
二、人工智能公共数据平台:AI时代的核心基础设施
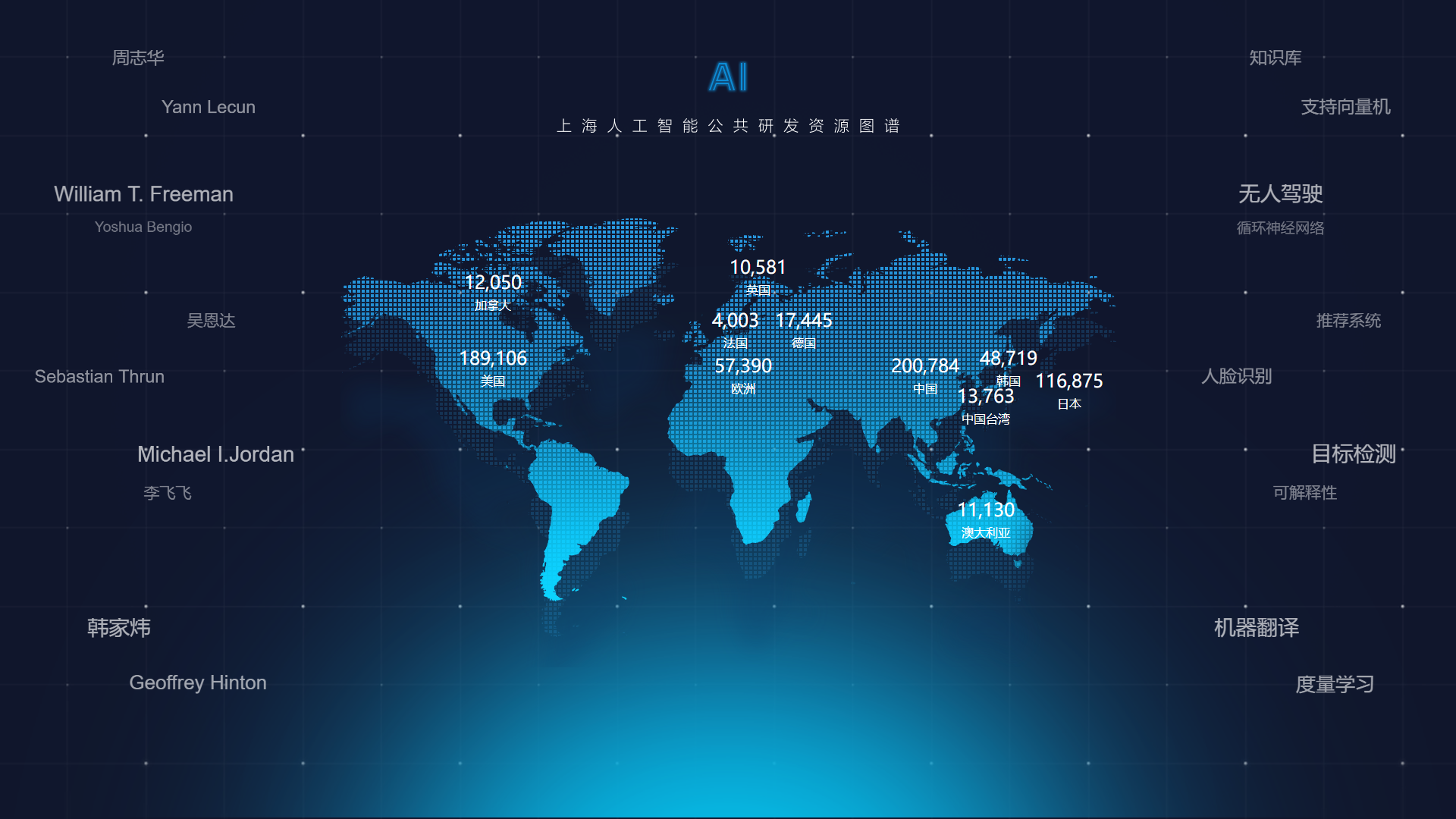
人工智能公共数据平台旨在汇聚、治理、开放和共享多源异构数据,为AI研发、应用创新和产业发展提供高质量、标准化、易获取的数据资源与服务。它是降低AI开发门槛、促进协同创新、保障数据安全与主权的基础性平台。当前此类平台面临数据体量巨大、处理实时性要求高、隐私安全保护严格、多任务并发负载重等多重挑战。
三、PIM技术与AI公共数据平台的融合前景
将PIM技术深度融入人工智能公共数据平台的架构中,有望从底层重塑其数据处理能力,催生新一代高性能、高能效、高安全的平台范式。
- 实现实时智能分析与决策:在公共数据平台上,政务、交通、医疗、环境等流数据源源不断。PIM技术能够支持在数据存储端进行实时的特征提取、模型推理(如异常检测、趋势预测),实现“数据即处理”,满足城市大脑、应急指挥等场景对毫秒级响应的需求,极大提升平台的服务响应能力。
- 赋能高效联邦学习与隐私计算:公共数据平台常涉及敏感数据,直接集中处理存在隐私风险。联邦学习允许数据不出本地进行模型训练。PIM硬件可以在各数据持有方的存储设备内高效完成本地模型训练与更新的计算,大幅提升联邦学习的效率,同时其硬件特性也有助于加固隐私计算(如安全多方计算)的执行环境,为数据“可用不可见”提供更可靠的硬件底座。
- 加速大规模预训练与模型服务:平台需要为AI开发者提供基础的预训练大模型服务。PIM架构特别适合大模型海量参数的高效加载与推理。通过将模型参数存储在具备计算能力的内存中,可以极大加速自注意力机制等核心运算,降低大模型服务的能耗与成本,使平台能够更经济地提供强大的模型即服务(MaaS)。
- 支撑异构数据统一处理:平台数据包括文本、图像、视频、传感器时序数据等。PIM架构的灵活性可以设计针对不同数据类型的专用存算单元,在近数据端完成特定预处理(如图像解码、特征编码),形成异构计算流水线,提升整体处理效率。
- 降低平台总体拥有成本(TCO):通过节省大量的数据搬运能耗和缩短任务处理时间,PIM技术能够显著降低数据中心的电力成本和硬件规模需求,这对于需要持续处理PB乃至EB级别数据的公共平台而言,意味着长期运营成本的实质性下降。
四、挑战与展望
尽管前景广阔,PIM技术在AI公共数据平台的规模化应用仍面临挑战,包括硬件生态成熟度、编程模型与软件栈的适配、不同PIM技术路径(如基于DRAM、新兴非易失存储器、或混合架构)的标准化等。
我们有望看到“PIM芯”与“AI平台”的协同进化:一方面,PIM硬件将变得更通用、更易编程;另一方面,AI公共数据平台的设计将从软件定义走向“软硬协同”定义,深度优化数据布局与计算任务调度以发挥PIM最大效能。两者的深度融合,将不仅加速AI自身的发展,更能强力赋能数字经济与社会治理,推动形成一个更高效、普惠、安全的人工智能数据基础设施,释放数据要素的倍增价值。